友情链接:

近日,DeepSeek与清华大学齐集发布了一篇题为《Inference-Time Scaling for Generalist Reward Modeling》的论文,建议了一种名为"自我原则点评调优(SPCT)"的全新学习门径女同 91,这项时刻冲破很可能成为行将发布的DeepSeek R2模子的中枢能力之一。这项研究不仅为通用奖励建模开垦了新旅途,更展示了如何通过优化推理阶段的盘算推算资源分拨来权贵提高大说话模子的性能,而无需增多模子参数目。

1.传统奖励模子的瓶颈与冲破
在大型说话模子(LLM)的磨砺中,强化学习(RL)已成为提高模子推理能力的关节时刻。然则,传统RL濒临一个根人性挑战:如安在空乏明确限定或可考据谜底的鄙俗畛域中,为模子提供准确的奖励信号。现存的奖励模子(RM)通常局限于特定畛域,难以妥贴万般化的查询场景。
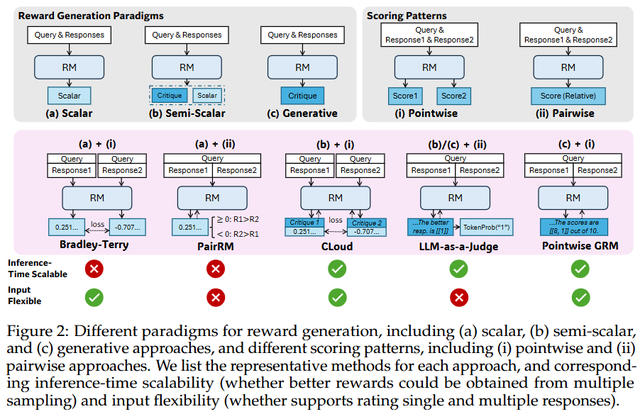
在线伦理片DeepSeek和清华的研究团队发现,接纳"点式生成式奖励建模(Pointwise GRM)"门径不错权贵提高模子的天真性。与传统的固定体式奖励模子不同,GRM或者拯救处理单个、成对和多个反映的评分,从而克服了体式不一致带来的挑战。这种门径的创新之处在于,它不再依赖预界说的原则来指令奖励生成,而是让模子自主生成评判原则,并阐述这些原则动态产生点评内容。
2.SPCT:自我进化的奖励生成机制
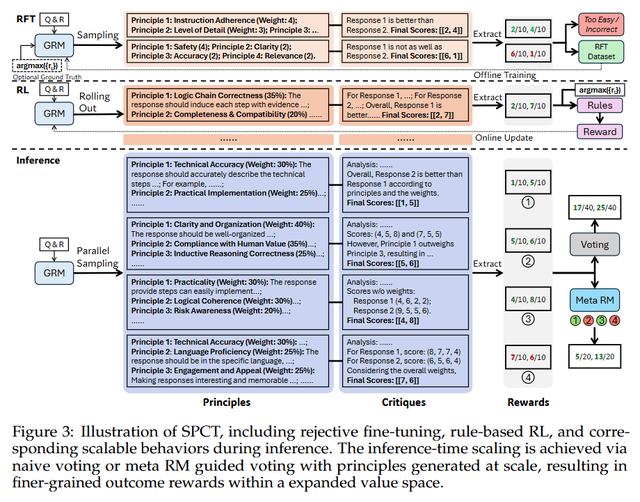
SPCT(Self-Principled Critique Tuning,自我原则点评调优)是这项研究的中枢创新,它包含两个关节阶段:
(1) 拒绝式微调阶段:看成"冷驱动",这一阶段让GRM妥贴不同输入类型,并学会以正确体式生成原则与点评内容。研究团队接纳了专有的拒绝战略——唯一当模子预测的奖励与真实奖励不一致,或者通盘采样遣散皆过于简单时,才会拒绝该轨迹。这种战略灵验幸免了数据偏差。
(2) 基于限定的在线强化学习阶段:在这一阶段,GRM通过不断优化生成的原则和点评内容来增强奖励生成能力。与DeepSeek此前的责任不同,研究者烧毁了体式奖励,转而接纳更高的KL处分统共来确保输出体式的正确性。
相配值得注目的是,SPCT将"原则"从传统的交融过程解耦出来,飘浮为奖励生成经由的一部分。这意味着模子不再被迫接纳预设原则,而是或者阐述输入问题和复兴内容动态生成评判步调,使奖励生成过程更具妥贴性。
3.推理时彭胀:用盘算推算资源一样性能提高
研究团队探索了如何诈骗更多推理盘算推算资源,通过基于采样的战略竣事存效的推理时彭胀。其中枢门径包括:
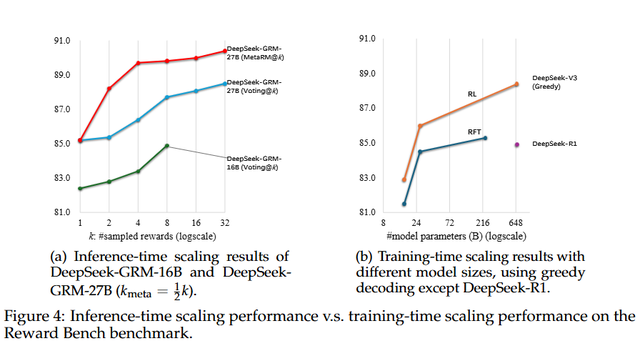
生成奖励投票机制:通过屡次采样生成不同的原则集和相应点评,然后对奖励进行投票乞降。这种门径本色上将奖励空间扩大了k倍,使GRM或者生成更丰富、更精良的评判视角。
元奖励模子指令:为了贬责就地采样可能带来的偏差问题,团队磨砺了一个元奖励模子(meta RM)来筛选高质地的采样遣散。实考据明,meta RM指令的投票能权贵提高最终奖励的质地和一致性。
基于Gemma-2-27B磨砺的DeepSeek-GRM-27B模子,在接纳32个样本告成投票时,其性能可与671B参数的更大模子相比好意思。而meta RM指令的投票仅需8个样本就能达到最好恶果,充分讲明了推理时彭胀的灵验性。
4.时刻冲破的本色预见
这项研究的价值不仅体目下时刻辩论上,更在于它为大型说话模子的发展提供了新想路:
性价比创新:比拟单纯扩大模子限制,推理时彭胀能以更低资本赢得可比以致更优的性能。这关于镌汰大模子应用门槛具有困难预见。
动态妥贴能力:自主生成原则的机制使模子或者更好地妥贴万般化的履行场景,不再受限于预设限定。这种天真性对构建果然的通用东谈主工智能至关困难。
可解释性提高:通过展示生成的原则和点评,用户不错更直不雅地交融模子的评判步调,增强了系统的透明度和的确度。
5.瞻望DeepSeek R2
天然DeepSeek官方尚未讲求公布R2的细节,但这项研究很可能预示着R2的中枢时刻标的。与R1主要依靠强化学习提高推理能力不同,R2可能会更留意推理阶段的优化和彭胀。
从时刻发展端倪看,DeepSeek正从"磨砺阶段优化"转向"推理阶段优化",这一排变与行业追求更高性价比的趋势高度一致。不错料到,R2将不仅在性能上有所冲破,更可能在资本效益和适用范围上带来惊喜。
跟着AI时刻插足深水区,像SPCT这么的创新标明女同 91,大模子的发展不再仅仅"更大更强",而是向着"更智能、更经济、更天真"的标的演进。DeepSeek R2的行将到来,或将再次刷新咱们对大型说话模子能力的剖析。